中央财经大学保险学院、中国精算研究院近日发布CUFEInse v1.0保险大模型评测基准的首次评测结果,这是全球首个专门针对保险领域的大语言模型专业评测。本次评测涵盖11个主流大模型,从5大核心维度、54项细分指标对模型能力进行全面评估。
评测概况
CUFEInse v1.0基准包含14,430道高质量题目,由中央财经大学专家团队命题,涵盖单选、多选、判断、简答、推理规划及复杂问答等题型。评测采用“维度等权、子类均衡”的综合评分策略,确保评估结果的全面性和可比性。
参与评测的11个模型如下:
模型名称 |
参数规模 |
模型类型 |
是否开源 |
推理能力 |
DeepSeek-R1-0528 |
671B |
通用 |
是 |
支持 |
Qwen3-32B-instruct |
32B |
通用 |
是 |
不支持 |
Qwen3-32B-think |
32B |
通用 |
是 |
支持 |
Qwen3-235B-A22B-instruct |
235B |
通用 |
是 |
不支持 |
Qwen3-235B-A22B-think |
235B |
通用 |
是 |
支持 |
Gemini-2.5-pro-0617 |
不详 |
通用 |
否 |
支持 |
GPT-4o-1120 |
不详 |
通用 |
否 |
支持 |
GPT-oss-120b |
120B |
通用 |
是 |
支持 |
AntGroup Finix-S1 |
不详 |
领域 |
否 |
支持 |
DianJin-R1 |
32B |
领域 |
是 |
支持 |
Fin-R1 |
7B |
领域 |
是 |
支持 |
综合排名揭晓
基于综合得分,参评模型分为三个梯队:
第一梯队(>85分):AntGroup Finix-S1(89.51分)、Gemini-2.5-Pro-0617(85.11分)
第二梯队(80-85分):DeepSeek-R1-0528(84.20分)、Qwen3-235B-A22B-think(83.03分)、Qwen3-235B-A22B-instruct(82.66分)、DianJin-R1(80.35分)、Qwen3-32B-think (80.34分)
第三梯队(<80分):Qwen3-32B-instruct(79.87分)、GPT-4o-1120(79.71分)、GPT-oss-120b(79.41分)、Fin-R1(71.46分)
各维度关键发现
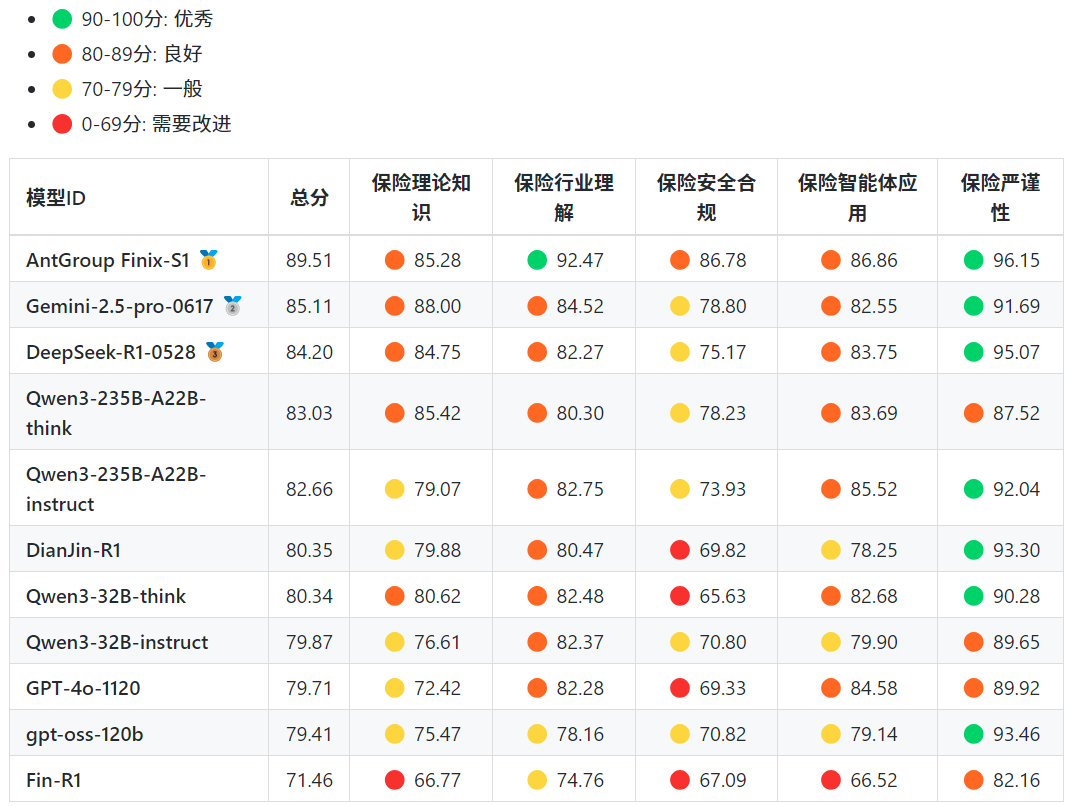
1. 理论知识维度:专业深度分化明显、推理模型优势突出
· Gemini-2.5-Pro-0617以88.00分位居第一,在保险精算(86.06分)等硬核领域表现突出
· AntGroup Finix-S1(85.28分)在保险法(93.05分)等细分领域排名第一,保险交叉领域知识覆盖较为全面
· 多数模型在保险精算方面得分偏低,反映非领域模型对保险核心量化知识掌握不足
· 同一基础模型的“推理版”表现优于“非推理版”,说明推理机制可帮助模型更好地整合专业知识,进行长思考和计算推理
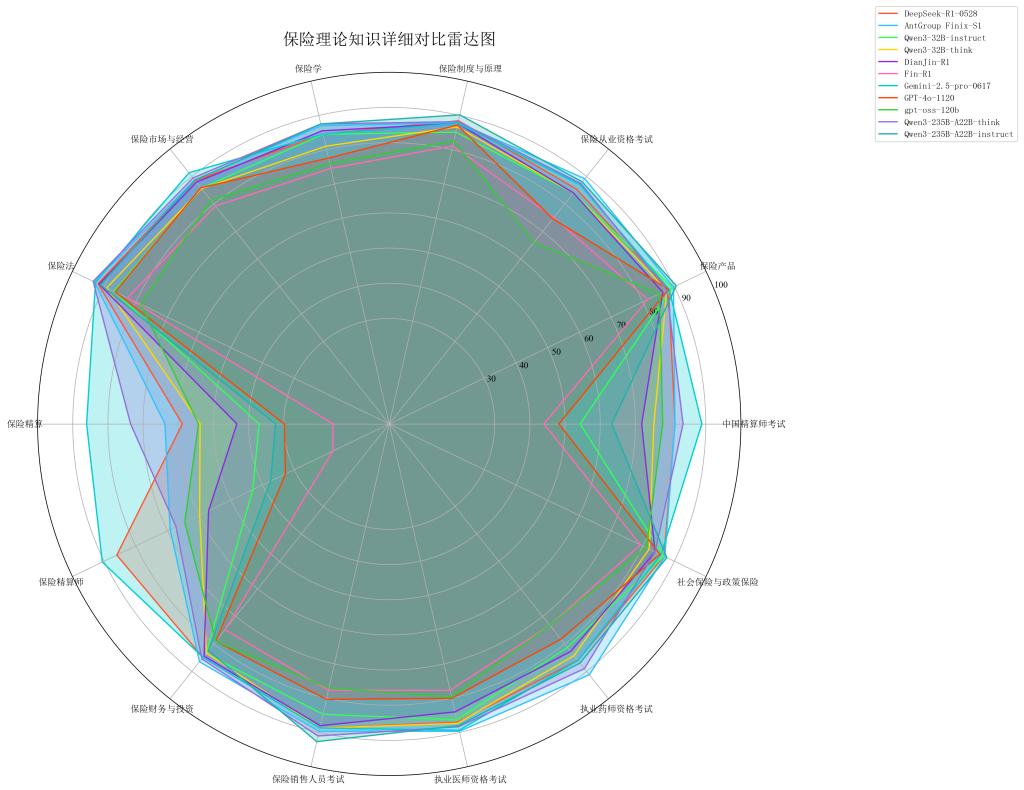
2. 行业理解维度:领域模型优势明显、场景适配性成关键
· AntGroup Finix-S1以92.47分领先,在18项子项中13项排名第一
· 医疗保险场景能力分化,业务流程覆盖不均,非领域模型在在体检报告疾病风险预测子项得分基本低于60分,在保险责任分析(平均得分60.1分)等场景存在明显短板现普遍较弱
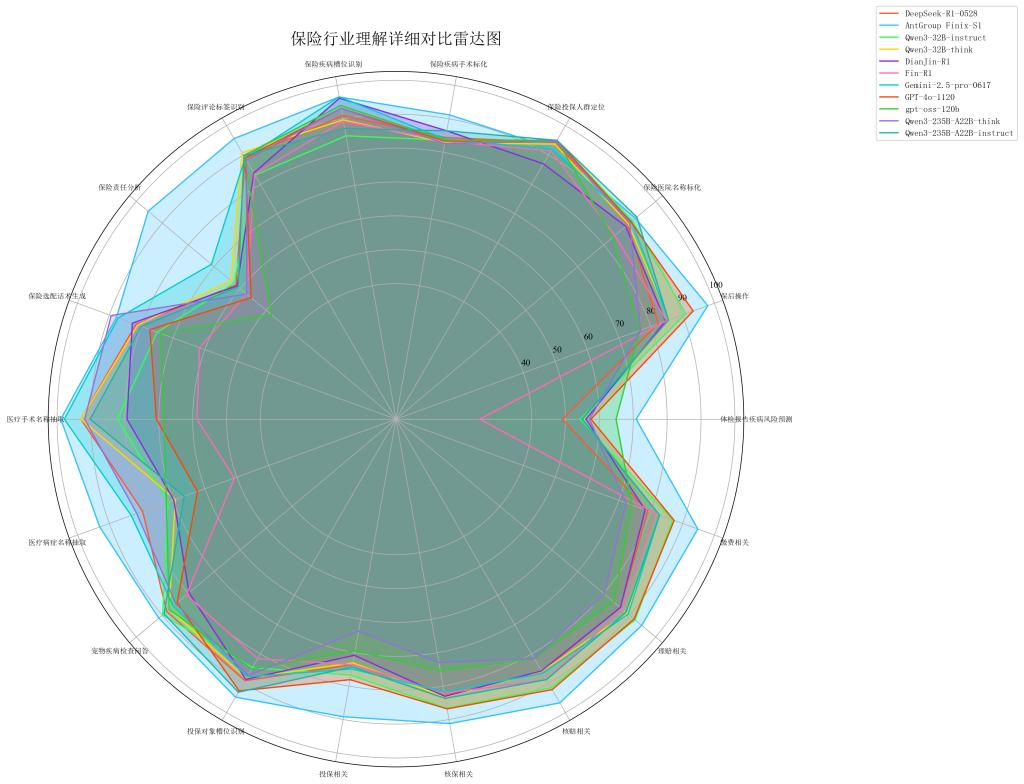
3. 安全合规维度:整体表现均衡、文案合规成行业痛点
· AntGroup Finix-S1以86.78分领先,其安全底线(92.67分)表现良好
· 所有模型在“保险文案合规”子项得分最高仅83.18分,最低46.83分,文案合规性是当前AIGC应用于保险营销的最大风险点之一
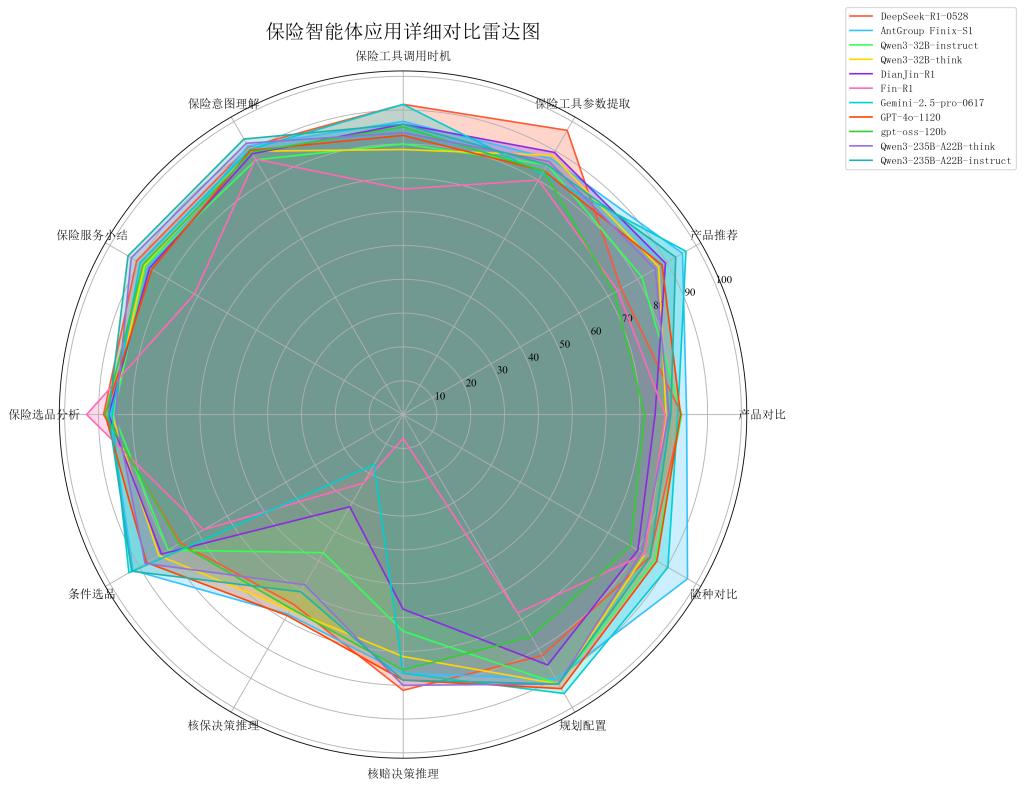
4. 智能体应用维度:能力梯度差异化、决策能力有待提升
· 智能体模型需要具有“理解需求-分析产品-决策建议-工具调用”的全流程智能服务能力,目前工具调用能力分化,各模型在险种对比等应用能力差异超过20分以上
· AntGroup Finix-S1以86.86分位列第一,在保险意图理解(91.67分)、产品推荐(95.35分)等关键能力上得分较高
· 非领域模型在核保决策推理、核赔决策推理子项表现相对较弱,决策推理能力是当前大模型在保险应用中的主要短板
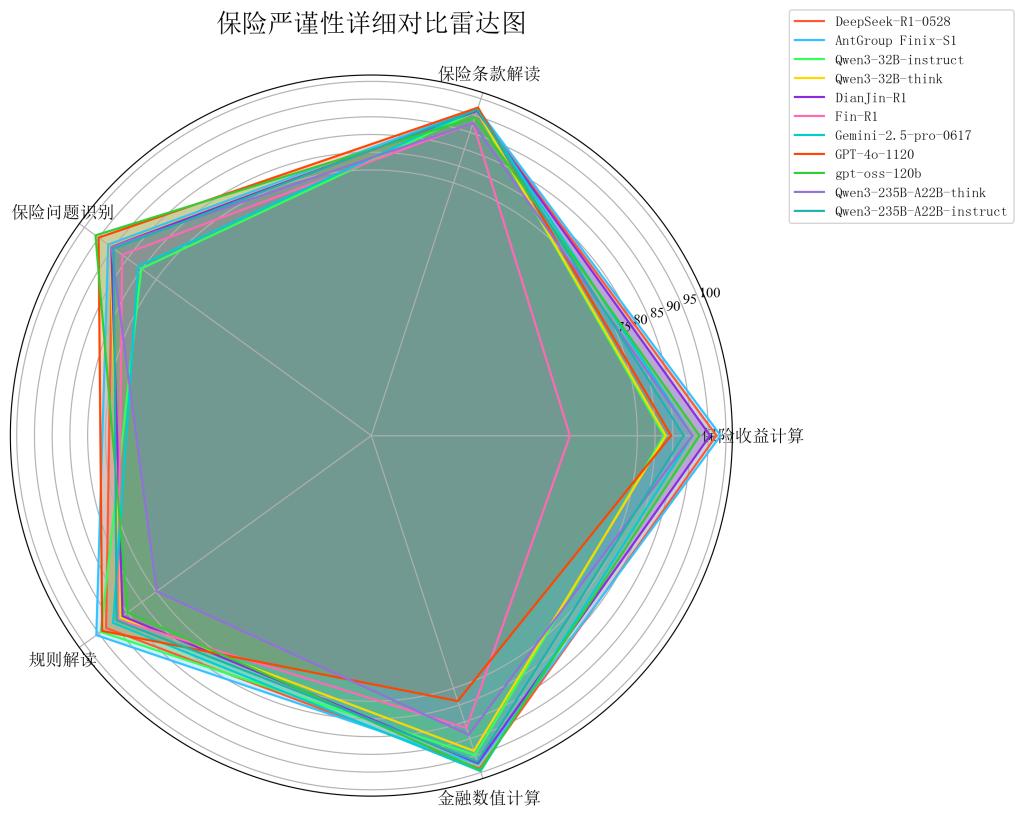
5. 逻辑严谨性维度:数值计算能力差异明显
· 计算能力分化显著:收益计算、数值计算分差在20-30分之间,AntGroup Finix-S1(96.15分)在保险收益计算(98.50分)等方面排名第一
· 问题识别能力普遍良好,GPT-oss-120b在保险问题识别(96.16分)表现优秀,能精准识别处理保险相关问题,显示通用模型在基础逻辑判断能力上依然稳健
核心洞见
1.高质量领域模型优势显著:AntGroup Finix-S1(蚂蚁保险⼤模型)作为保险领域模型,以 89.51 分位列综合第一,显示高质量的领域适配训练对保险⼤模型具有积极意义;
2.通用模型有亮点但不全面:Gemini-2.5-Pro-0617(通⽤模型)在保险理论维度排名第一,显示通用大模型在知识广度上的优势,但在智能体应⽤(82.55分)和安全合规(78.80分)上还有提升空间,体现出“通⽤能⼒强但部分领域适配不⾜”的特点;
3.推理机制价值验证:同⼀基础模型的“推理版”在保险理论、逻辑严谨性等表现均优于“⾮推理版”,说明推理机制可有效提升模型对保险复杂推理任务与多步计算的整合应⽤能⼒;
4.行业共性瓶颈识别:硬核专业领域普遍得分偏低,保险精算、核保核赔决策、文案合规性成为当前大模型在保险领域的三大共性瓶颈,⾮领域模型在保险业务全流程适配、⼩众场景如体检报告⻛险预测上存在明显短板,需针对性优化。
优化建议
基于评测结果,研究团队提出以下建议:
1. 针对领域模型:重点提升保险精算等专业深度,补充细分保险场景(如宠物险、农业险)的业务数据,进一步巩固"全场景+高专业"优势;
2. 针对非领域模型:增加保险业务全流程(投保-核保-理赔)的场景化训练,强化"保险+医疗""保险+精算"交叉领域的知识融合,提升领域适配性;
3. 针对开源模型:提供保险领域微调数据集(尤其是精算、核保核赔场景),降低开发者的领域适配门槛,推动开源保险大模型的生态建设;
4. 针对弱势模型:从基础保险理论体系搭建入手,优先补充保险精算、合规价值观等核心知识,逐步拓展业务场景,实现"从基础到应用"的阶梯式提升。
未来展望
CUFEInse保险大模型评测基准将持续迭代,逐步纳入多模态能力评估、实时监管政策适应性测试等新维度,助力保险行业数字化转型。
我们相信,随着领域模型的持续优化与通用模型领域适配能力的提升,大语言模型将在保险产品设计、精准营销、智能核保、理赔服务等全流程中发挥更大价值,最终推动保险服务向更加智能化、个性化、高效化的方向发展。
中央财经大学保险学院、中国精算研究院将继续秉持开放合作的态度,欢迎业界与学界共同参与CUFEInse基准的迭代与完善,共同推动保险科技生态的繁荣发展。
📊 开源评测集与完整评测报告地址:
·GitHub:https://github.com/CUFEInse/CUFEInse
·Hugging Face:https://huggingface.co/datasets/CUFEInse/CUFEInse
📧 联系我们:cufeinse@cufe.edu.cn
🏢 发布机构:中央财经大学保险学院、中国精算研究院
(撰稿:马冰;审稿:周桦;编辑:王维;审核:周桦、吕丽)





